Introduction to Vectorless RAG
The landscape of Large Language Models (LLMs) is continuously evolving, with innovations aimed at enhancing their ability to deliver accurate, contextually relevant, and cost-effective responses. Retrieval Augmented Generation (RAG) emerged as a pivotal technique to ground LLMs in external knowledge, mitigating issues like hallucination and outdated information. However, traditional RAG, heavily reliant on vector embeddings, presents its own set of challenges. This article explores a revolutionary alternative: Vectorless RAG, a reasoning-based approach that promises to transform how LLMs interact with complex documents.
Understanding Retrieval Augmented Generation (RAG)
At its core, RAG is a methodology that augments an LLM's inherent knowledge with retrieved information from an external database, allowing it to generate more informed and precise answers. Before RAG, a "naive LLM approach" involved directly feeding an LLM the user's query along with all potentially relevant documents.
This naive approach quickly runs into significant problems:
- Limited Context Window: LLMs have a finite "context window," which is the maximum amount of text (measured in tokens) they can process in a single request. Think of it as the model's working memory. If the input, including the query, conversation history, and provided documents, exceeds this limit, the model cannot process it all. This limitation stems from the transformer architecture, where the computational complexity of self-attention grows quadratically with the context length, making very long contexts computationally expensive and slow. For instance, models like Llama 2 might have a context window of 4,000 tokens, while more advanced models like Claude 2 can handle up to 100,000 tokens, and GPT-4.1 up to 128,000 tokens.
- Quality & Hallucination: When an LLM is given too much context, or context that is not precisely relevant, it can struggle to focus on the most pertinent information. This can lead to less focused answers, or worse, "hallucination," where the model confidently outputs information that is incorrect, meaningless, or fabricated. Hallucinations are a major barrier to adopting LLMs in high-stakes fields requiring factual precision.
- Cost: LLM pricing is typically based on the number of tokens processed (both input and output). Sending massive documents to an LLM for every query results in high token counts and, consequently, high operational costs per API call.
The Traditional Approach: Vector-Based RAG
Traditional RAG addresses these problems by introducing a two-phase process:
1. Indexing Phase
During this phase, documents are prepared for efficient retrieval:
- Chunking: Large documents are divided into smaller, manageable segments or "chunks." Common chunking strategies include splitting by page, paragraph, or fixed token windows (e.g., 500 words).
-
Embedding/Vectorization: Each text chunk is then
converted into a numerical representation called a
vector embedding. This process uses specialized
embedding models (e.g.,
text-embedding-3-large) that capture the semantic meaning of the text. Chunks with similar meanings will have vectors that are numerically "close" to each other in a multi-dimensional space. - Vector Database (Vector DB): These generated vector embeddings, along with their corresponding original text chunks, are stored in a specialized database known as a vector database (e.g., Pinecone, ChromaDB). This database is optimized for rapid similarity searches.
2. Query Phase
When a user submits a query:
- User Query Embedding: The user's natural language query is also converted into a vector embedding using the same embedding model.
-
Vector Similarity Search (VSS): This query vector is
then used to perform a similarity search within the vector database. The
system retrieves the
top_k(e.g., top 5 or 10) most "similar" vectors, which correspond to the most semantically relevant chunks from the original documents. - LLM Generation: These retrieved, relevant chunks (a focused subset of the original document) are then combined with the user's query and fed into the LLM. With a more concise and relevant context, the LLM can generate a more accurate, contextual, and less hallucinatory answer.
The Problems with Traditional (Vector-Based) RAG
Despite its effectiveness, traditional vector-based RAG is not without limitations, especially when dealing with complex or highly structured documents:
- Blind Chunking: Arbitrary chunking strategies, such as splitting documents into fixed-size windows (e.g., 500 words), often disrupt the natural flow of information. This can cut logical connections, leading to loss of context within chunks or fragmenting crucial information across multiple chunks. For instance, a sentence referring to a table on the same page might be separated, making the retrieved chunk less meaningful.
- Context Loss & Broken Narratives: Critical information necessary to answer a query might be fragmented across several chunks. If only some of these fragmented pieces are retrieved, or if the most vital part is missed, the LLM receives an incomplete narrative. This can be particularly problematic in legal documents with cross-references between pages or narratives where a key event spans multiple paragraphs that are then split.
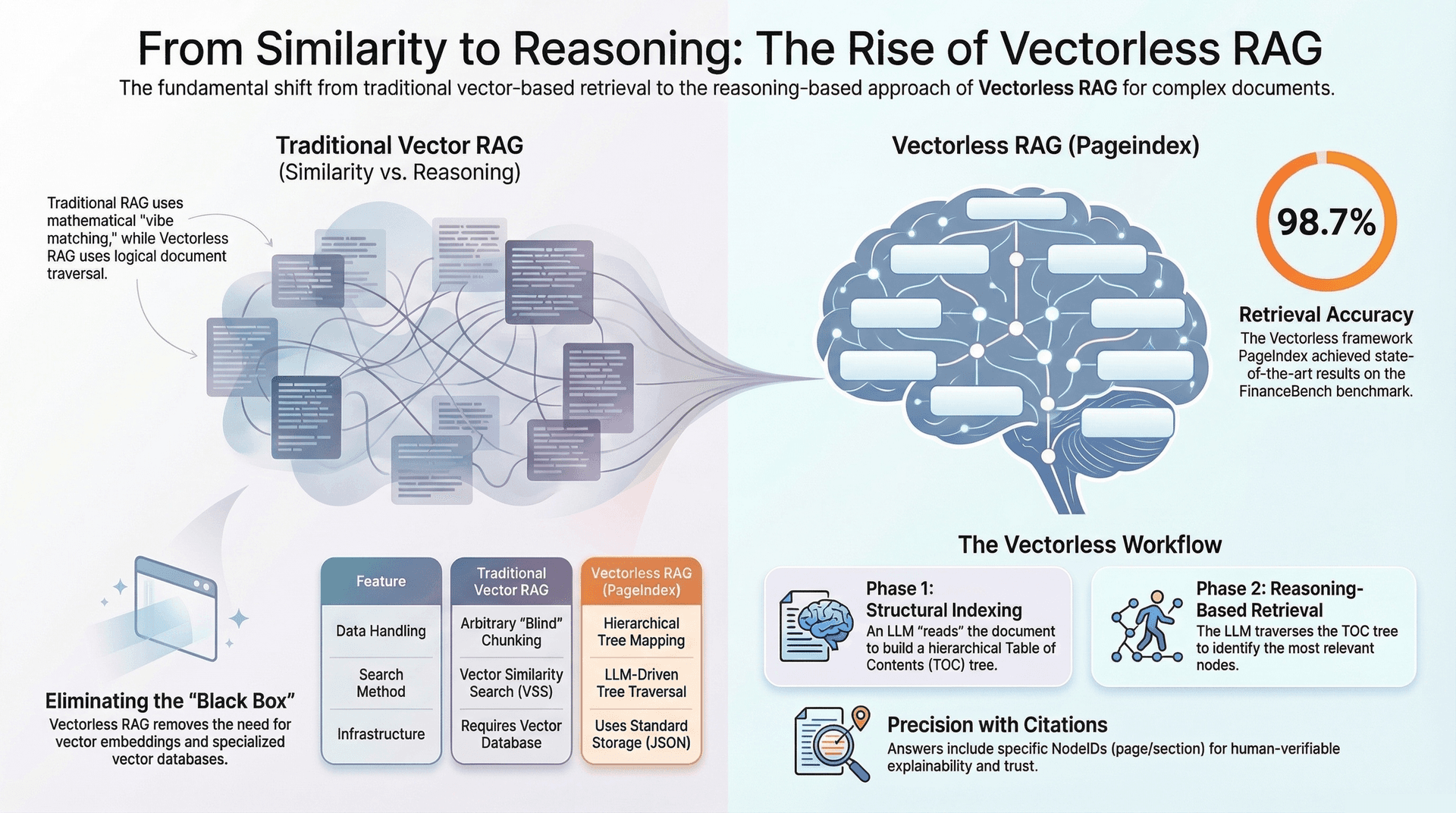
- Similarity vs. Reasoning: Vector similarity relies on the semantic closeness of word embeddings. However, semantic similarity does not always equate to logical relevance or deep understanding. A retrieved chunk might be semantically similar to the query ("vibe matching") but narratively or logically irrelevant to formulating a precise answer. For example, two passages in a financial report might both mention "revenue," but one could be about historical trends while the other is about future projections. A vector search might retrieve both equally, even if only one is truly relevant to the query.
- Lack of Explainability/Traceability: The process of vector similarity search can often feel like a "black box." It's challenging to understand why certain chunks were retrieved over others, making it difficult to debug or trace the reasoning behind an LLM's answer back to specific parts of the source document beyond a general similarity score. This lack of transparency can hinder trust and validation, especially in regulated industries.
Introducing Vectorless RAG (PageIndex): A Reasoning-Based Approach
Recognizing the limitations of vector-based RAG, a new paradigm called Vectorless RAG, exemplified by frameworks like PageIndex, has emerged. This approach fundamentally shifts from "Similarity to Reasoning" and emphasizes "Structure Before Search." The core idea is to leverage the document's inherent logical and hierarchical structure, rather than relying on abstract vector embeddings and arbitrary chunks. Notably, this method eliminates the need for vector embeddings, vector databases, and artificial chunking.
Vectorless RAG operates in two distinct phases:
Phase 1: Creating the Tree (Indexing Phase - "Structural Indexing")
Instead of transforming text into vectors, Vectorless RAG focuses on understanding and mapping the document's intrinsic structure:
- Structural Detection: An LLM is employed to "read" the entire document (e.g., a financial report, a legal contract, a movie script). Its task is to identify natural boundaries and logical divisions within the text. This could include scene headings, character introductions, major narrative transitions, chapter titles, section headers, or subsections.
- Hierarchical Table of Contents (TOC) Tree: Based on this structural detection, the LLM constructs a hierarchical tree that represents the document's inherent organization. This is akin to building a highly intelligent, detailed table of contents, but optimized for machine comprehension.
-
Node Content: Each node within this tree stores
critical information:
- A concise
titleof the section it represents. -
A
nodeId(a unique identifier or a pointer/reference to the original location, such as page number, of that section in the document). -
A brief
summaryof the section, generated by the LLM, capturing its main points. -
References to its
child nodes(sub-sections), establishing the hierarchy.
- A concise
This entire process is an intelligent, reasoning-based approach to map the document's content, preserving its semantic and structural integrity.
Phase 2: The Query Phase (Reasoning-Based Retrieval)
When a user submits a query, the Vectorless RAG system performs a sophisticated, reasoning-driven retrieval:
- LLM Receives: The LLM is provided with the user's natural language question, the complete hierarchical map (the JSON tree of the document's structure), and the summaries of each node in the tree.
- Structural Search (Tree Traversal): The LLM then utilizes its inherent reasoning capabilities to traverse this TOC tree. It acts like a human expert navigating a book's table of contents and chapter summaries, logically identifying the most relevant nodes/sections based on the query. This is a deliberate, step-by-step search, rather than a probabilistic similarity match.
-
Deep Dive/Extraction: Once the LLM identifies the
relevant nodes through its logical traversal, their associated
nodeId(pointer) is used to retrieve only the specific raw text from those focused sections of the original document. This ensures that the retrieved context is highly targeted and relevant. -
Final Answer: This highly focused, context-rich text,
combined with the original user query, is then sent to the LLM for
precise answer generation. A significant advantage is the LLM's ability
to cite the original
nodeId(e.g., page number or section title) for enhanced explainability and traceability.
Why Vectorless RAG Shines
Vectorless RAG offers several compelling advantages, particularly for handling complex, structured information:
- Human-like Reading: This approach mimics how humans naturally navigate and extract information from complex documents. Instead of skimming random pages (like a vector search), a human consults the table of contents, reads section summaries, and then dives into specific chapters for detail – precisely what Vectorless RAG enables the LLM to do.
- Improved Accuracy: By deeply understanding the document's structure and reasoning over summaries, Vectorless RAG avoids the pitfalls of arbitrary chunking and superficial semantic similarity. This leads to more precise retrieval of relevant context and, consequently, more accurate LLM responses. For example, PageIndex, a vectorless RAG framework, achieved a state-of-the-art 98.7% accuracy on FinanceBench, a benchmark for financial document analysis.
-
Better Explainability and Traceability: The retrieval
process in Vectorless RAG is logical and based on the document's
explicit structure. This means it's much easier to understand
why certain information was retrieved, as the LLM can trace its
"thought process" through the tree, often citing specific
nodeIds(e.g., page numbers or section titles) in its answers. This transparency is crucial for auditing and building trust in AI systems. - No Vector Database Overhead: By eliminating the need for vector embeddings and specialized vector databases, Vectorless RAG simplifies the infrastructure stack. This can lead to reduced operational complexity and potentially lower maintenance costs.
- Effective for Structured Documents: This approach is particularly powerful for long-form documents that inherently possess a clear, hierarchical organization. Examples include financial reports, legal contracts, regulatory filings, academic papers, policy manuals, and technical specifications, where understanding the relationship between sections is paramount.
- LLM Navigates, Not Guesses: Instead of merely relying on mathematical similarity scores to guess relevance, the LLM in a Vectorless RAG system actively uses its reasoning capabilities to navigate the document structure and find the answer.
Trade-offs to Consider
While Vectorless RAG presents significant advancements, it's important to acknowledge its trade-offs:
- Computational Cost: The initial indexing phase, which involves an LLM reading and structuring the entire document, can be more computationally intensive and expensive than simply generating embeddings for chunks. Similarly, the LLM-driven tree traversal during the query phase requires more reasoning cycles than a fast vector similarity search.
- Latency: The reasoning process involved in both indexing and retrieval might introduce slightly higher latency compared to the near-instantaneous mathematical operations of a vector similarity search, especially for very large documents or complex queries.
- Document Suitability: Vectorless RAG thrives on documents with (or from which an LLM can effectively derive) a clear, hierarchical structure. For highly unstructured data, such as conversational logs, diverse web pages, or collections of short, disparate documents that lack explicit organization, traditional vector-based RAG might still be a more appropriate or complementary solution.
Conclusion
The emergence of Vectorless RAG marks a significant evolution in how Large Language Models can effectively leverage external knowledge. By prioritizing "Structure Before Search" and employing "Reasoning, Not Similarity," this approach promises to deliver more accurate, explainable, and contextually rich answers, especially for complex and structured documents. While traditional vector-based RAG remains valuable for certain use cases, Vectorless RAG offers a compelling alternative that pushes the boundaries of LLM capabilities, moving towards a more human-like understanding and navigation of information. The future of RAG likely lies in hybrid approaches that intelligently combine these methods, leveraging the strengths of each based on the specific query and data characteristics.
Further Reading
- Advanced RAG Techniques
- LLM Context Window Optimization
- Knowledge Graphs in LLM Applications
- Hybrid Retrieval Systems for AI
- Semantic Search vs. Lexical Search