How Recursive Language Models Are Solving AI Memory
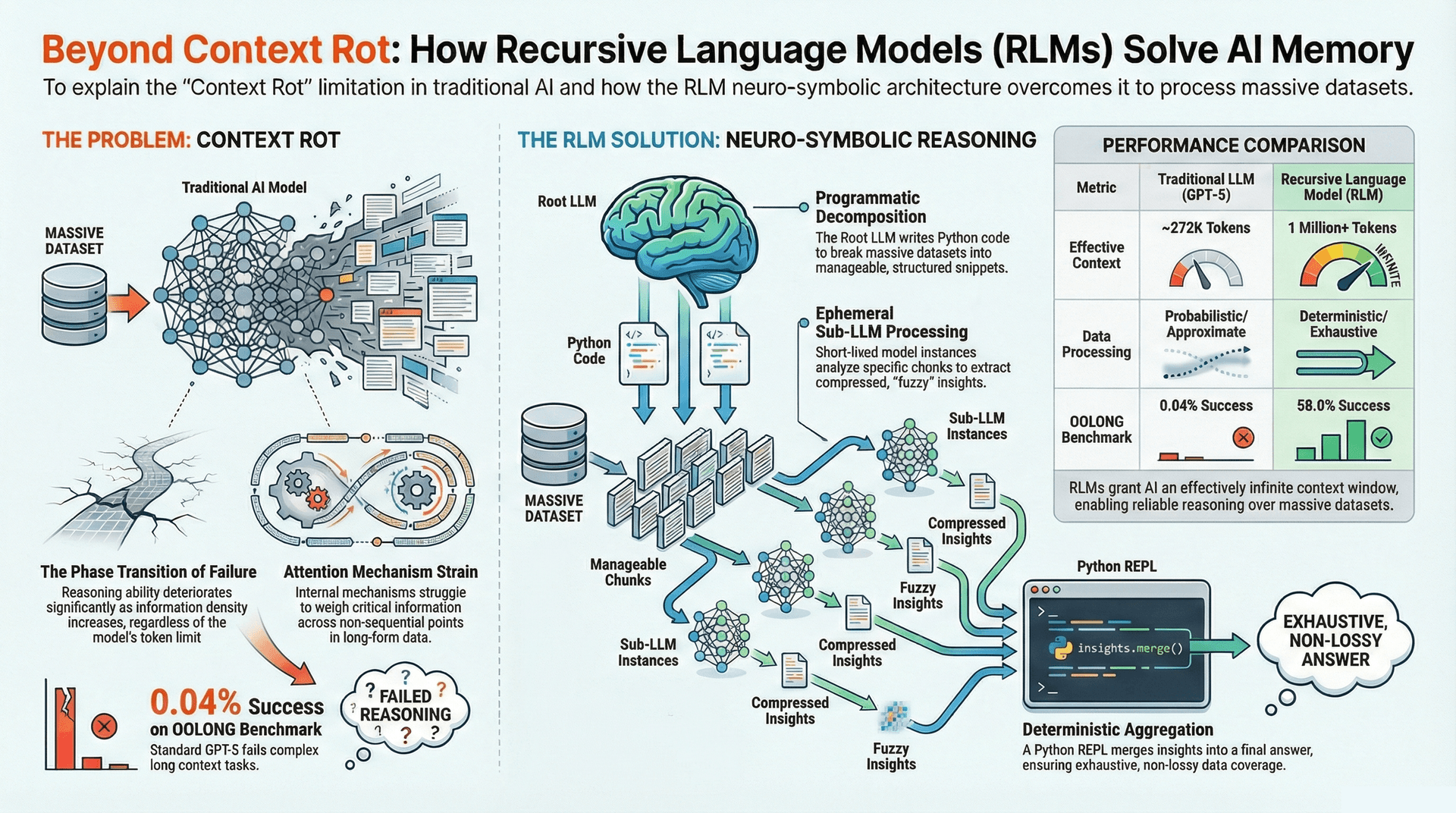
The landscape of Artificial Intelligence is continuously evolving, with Large Language Models (LLMs) at the forefront of recent advancements. However, despite their impressive capabilities, LLMs face inherent limitations, particularly when handling extensive and complex information. One such critical challenge is "Context Rot," a phenomenon where an LLM's reasoning ability deteriorates significantly as the input context length increases, especially in tasks requiring high information density. This issue persists even with the advent of LLMs boasting massive token limits, rendering complex long-context problems "solved-in-name-only."
This blog post delves into a groundbreaking solution developed by MIT CSAIL: Recursive Language Models (RLMs). RLMs represent a significant phase shift in AI, moving beyond the traditional LLM paradigm to offer a robust mechanism for overcoming context limitations and enhancing reasoning over vast datasets.
Understanding the "Context Rot" Problem in LLMs
Large Language Models (LLMs) are sophisticated neural networks trained on vast amounts of text data, enabling them to understand, generate, and process human language. A crucial aspect of their operation is the context window, which refers to the maximum amount of input text (measured in tokens - words or sub-word units) an LLM can process at once to generate a coherent response.
The challenge arises when tasks become information-dense, meaning they require the model to synthesize information from numerous, often non-sequential, points within a long input. In such scenarios, LLMs often exhibit "Context Rot." This degradation occurs because their internal attention mechanisms - the components responsible for weighing the importance of different parts of the input - undergo a "phase transition." Effectively, as the required reasoning density increases, the attention mechanisms struggle to maintain coherence and identify critical information across the extended context, leading to a drastic drop in performance.
Imagine an LLM trying to find subtle correlations across a 100-page legal document. While it might perform well on a short query, asking it to identify all clauses related to a specific, deeply embedded concept that spans multiple, non-contiguous sections becomes increasingly difficult.
Here's an infographical representation of Context Rot:
graph TD
A[Start Short Context] --> B{High Performance};
B --> C[Increased Context Length];
C --> D{Information Density Increases};
D --> E[Attention Mechanism Strain];
E --> F{Coherence Degradation};
F --> G[Context Rot Low Performance];
style A fill:#D4EDDA,stroke:#28A745,stroke-width:2px;
style B fill:#C3E6CB,stroke:#28A745,stroke-width:2px;
style C fill:#FFE0B2,stroke:#FF8F00,stroke-width:2px;
style D fill:#FFCC80,stroke:#FF8F00,stroke-width:2px;
style E fill:#FFAB91,stroke:#E64A19,stroke-width:2px;
style F fill:#FF8A65,stroke:#E64A19,stroke-width:2px;
style G fill:#FFCDD2,stroke:#D32F2F,stroke-width:2px;
click A "Start with a short, manageable context for the LLM."
click B "LLM demonstrates high reasoning and comprehension."
click C "User provides a longer input, approaching the context window limit."
click D "The task requires extracting nuanced information from scattered parts of the long input."
click E "The LLM's attention mechanisms struggle to track all relevant dependencies."
click F "The model loses track of crucial details and relationships within the context."
click G "Performance significantly degrades, leading to incorrect or incomplete answers."
Introducing Recursive Language Models (RLMs)
MIT CSAIL's answer to Context Rot comes in the form of Recursive Language Models (RLMs). This innovative approach fundamentally redefines how LLMs interact with large prompts. Instead of feeding an entire long prompt directly into the neural network, RLMs treat the prompt as an object residing in an external environment.
The core innovation of RLMs lies in their ability to programmatically examine, decompose, and recursively process snippets of the prompt by writing Python code. This code is executed in a Read-Eval-Print Loop (REPL).
A Read-Eval-Print Loop (REPL) is an interactive programming environment that takes single user inputs, executes them, and returns the result to the user. Familiar examples include the Python interpreter itself, where you type a command, press Enter, and get an immediate output. In RLMs, the LLM itself generates the commands for the REPL.
This design allows the LLM to orchestrate its own reasoning process, breaking down complex tasks into manageable sub-problems, much like a human programmer would approach a large dataset.
graph TD
A[Long Prompt/Dataset] --> B[RLM Root LLM];
B --> C{Generates Python Code};
C --> D[Python REPL External Environment];
D --> E{Executes Code};
E -- Calls llm_query() --> F[Sub-LLM Instance Ephemeral];
F -- Processes Snippet --> G[Compressed Insight];
G --> D;
D -- Returns Result --> B;
B --> H[Synthesizes Final Answer];
style A fill:#E3F2FD,stroke:#2196F3,stroke-width:2px;
style B fill:#BBDEFB,stroke:#2196F3,stroke-width:2px;
style C fill:#90CAF9,stroke:#2196F3,stroke-width:2px;
style D fill:#B3E5FC,stroke:#03A9F4,stroke-width:2px;
style E fill:#81D4FA,stroke:#03A9F4,stroke-width:2px;
style F fill:#C8E6C9,stroke:#4CAF50,stroke-width:2px;
style G fill:#A5D6A7,stroke:#4CAF50,stroke-width:2px;
style H fill:#DCEDC8,stroke:#8BC34A,stroke-width:2px;
RLM's Architectural Blueprint
The power of RLMs stems from their distinct architectural components working in concert:
- The Root LLM Architect: This is the primary model instance. Crucially, its own context window remains largely empty. Its core function is strictly code generation and orchestration. It doesn't directly process the vast raw data but rather sees variable names and structural information provided by the REPL. It acts as the intelligent programmer, deciding what code to write to solve the problem.
- The Python REPL Engine: Serving as the external environment, the REPL is the workhorse for
"hard logic" that LLMs typically struggle with. This includes deterministic operations like
counting, exact indexing, executing loops, and holding massive string variables in memory.
It executes the Python code generated by the Root LLM and provides a special
llm_query()function that acts as a bridge to the neural components. - The Sub-LLMs Workers: These are ephemeral (short-lived) instances of an LLM, spawned by the
llm_query()function within the executed Python code. Each Sub-LLM receives a specific, manageable chunk of data from the external environment. Their role is to handle the "fuzzy logic" tasks: reading, summarizing, extracting key information, or answering questions based on their assigned snippet. They return a compressed insight, which the REPL then makes available to the Root LLM.
The Recursive Trajectory: A Four-Phase Process
RLMs execute tasks through a systematic, four-phase recursive trajectory:
- Probing: The process begins with the Root LLM writing Python code to inspect the structure
of the input data. For example, it might generate code to
read_file('document.csv').head(5)to determine if the data is a CSV and understand its initial format. This initial exploration helps the RLM formulate a plan. - Decomposition: Based on the probing, the Root LLM writes a Python loop to iterate over the entire context. This loop defines how the larger problem will be broken down into smaller, manageable parts. For instance, it might loop through lines of a file, paragraphs of a document, or entries in a list.
- Recursion: Inside this loop, the Root LLM generates calls to the
llm_query()function. Each call effectively spawns a fresh, ephemeral instance of a Sub-LLM. This Sub-LLM receives a specific chunk of data (e.g., a single line, a paragraph) and a specific instruction. With its own empty context window, it processes this small chunk to extract a compressed insight or answer, which is then returned to the REPL. - Aggregation: As the loop completes, the Root LLM collects all the outputs from the Sub-LLM calls (the compressed insights). It then writes final Python code to synthesize these collected results into the ultimate answer, leveraging the REPL's deterministic capabilities for final assembly or calculation.
This structured approach ensures that no part of the context is missed, and the LLM's core reasoning ability is applied only to relevant, focused segments.
RLM vs. Traditional LLM + RAG
To appreciate the innovation of RLMs, it's helpful to contrast them with a commonly used technique for extending LLM capabilities: Retrieval Augmented Generation (RAG).
Retrieval Augmented Generation (RAG) is an AI framework that enhances the factual accuracy and relevance of LLM-generated responses by retrieving information from external knowledge bases. Instead of relying solely on its internal training data, an LLM equipped with RAG first performs a search query on a provided document store (e.g., a vector database) to retrieve relevant snippets, and then uses these snippets as additional context to formulate its answer.
| Feature | Traditional LLM + RAG | Recursive Language Models (RLM) |
|---|---|---|
| Approach | Probabilistic and approximate retrieval | Deterministic and exhaustive processing |
| Coverage | O(1) or O(logN) retrieval; hopes vector search finds relevant info | O(N) or O(N^2) coverage; guarantees iteration through data via code |
| Complexity | Often fails on complex, information-dense tasks | Excels at complex tasks requiring deep, structured reasoning |
| Retrieval | Lossy; relies on vector embeddings and similarity search; summarization can lose detail | Exact; programmatic iteration via Python code ensures full data traversal |
| Reasoning Flow | LLM receives retrieved snippets as extended context, then reasons directly | LLM orchestrates sub-calls, applies reasoning to small chunks, aggregates |
| Mechanism | Vector database for semantic search | Python REPL for symbolic logic, iteration, and Sub-LLM orchestration |
Standard RAG is fundamentally probabilistic and approximate. It relies on vector search to hope it finds the right information. While effective for many tasks, it often fails on highly complex queries because the retrieval process can be lossy, and summarization of retrieved documents can lead to a critical loss of detail. RAG is like asking a librarian to find books that might be relevant and then summarizing them; it's efficient but can miss specific details.
RLM, on the other hand, is deterministic and exhaustive. By generating Python code to iterate through the data, it guarantees O(N) or even O(N^2) coverage of the input, depending on the task's complexity. It's like having a meticulous research assistant who systematically reads every relevant page, making sure no detail is overlooked, and then compiling precise notes.
graph TD
subgraph RAG Approach
A[Large Corpus] --> B(Vector Database);
C[User Query] --> D{Vector Search};
D -- Probabilistic Retrieval --> E[Relevant Snippets];
E --> F[LLM with Extended Context];
F --> G[Approximate Answer];
end
subgraph RLM Approach
H[Large Corpus] --> I(Python REPL);
J[User Query] --> K[Root LLM Architect];
K -- Generates Iteration Code --> I;
I -- Iterates Data --> L[Sub-LLM Instance Chunk];
L -- Extracts Precise Insight --> I;
I -- Aggregates Insights --> K;
K --> M[Deterministic, Comprehensive Answer];
end
classDef probabilistic fill:#FFECB3,stroke:#FFC107,stroke-width:2px;
classDef deterministic fill:#DCEDC8,stroke:#8BC34A,stroke-width:2px;
B:::probabilistic; D:::probabilistic; E:::probabilistic; F:::probabilistic; G:::probabilistic;
I:::deterministic; K:::deterministic; L:::deterministic; M:::deterministic;
Unprecedented Performance and Cost Efficiency
The practical implications of RLMs are profound. They demonstrate significant improvements across key metrics:
- Extended Effective Context Window: RLMs have successfully extended the effective token context window to 1 million+ tokens, a monumental leap compared to even advanced models like GPT-5, which typically operate around 272K tokens. This enables processing of entire books, extensive legal documents, or large codebases with unprecedented detail.
- Drastic Performance Gains: On complex, long-context benchmarks, RLMs showcase superior performance. For instance, on "OOLONG-Pairs" - a quadratic complexity task with a 32,000-token context slice designed to test an LLM's ability to find specific pairs across a large input - a base GPT-5 model scored a mere 0.04%. In stark contrast, an RLM wrapper on GPT-5 achieved an impressive 58.0%. Similar dramatic improvements have been observed across benchmarks like CodeQA, BrowseComp+, and OOLONG, outperforming base models and other methods like CodeAct and Summary Agents.
- Cost Efficiency: Remarkably, RLM (with or without sub-calls) often demonstrates lower average API costs per query compared to direct LLM calls at higher context lengths. By strategically segmenting and processing data, RLMs optimize resource usage, making complex, long-context tasks more economically viable.
The Dawn of Neuro-Symbolic AI: A Paradigm Shift
The fundamental success of RLMs delivers a powerful scientific verdict: "Attention Is Not All You Need." While the attention mechanism is highly effective for local reasoning within a constrained context, it falls short when confronted with global, high-density reasoning over massive datasets.
RLMs underscore the critical importance of Neuro-Symbolic systems. A Neuro-Symbolic system combines the strengths of neural networks (which excel at pattern recognition, fuzzy intuition, and learning from data) with symbolic AI (which excel at logical reasoning, explicit knowledge representation, and structured problem-solving).
In the RLM framework:
- Neural Networks (the
llm_query()function and Sub-LLMs) provide the "fuzzy intuition," enabling them to read, understand, and extract nuanced insights from unstructured text snippets. - Symbolic Logic (the Python code and REPL) provides the "rigid structure," orchestrating the entire process - controlling loops, managing data flow, performing deterministic operations, and ensuring comprehensive coverage.
This elegant combination allows AI to tackle problems that require both intuitive understanding and precise, structured execution. If a model can recursively decompose a problem and "read" an external environment (like a disk or a large database) via generated code, it effectively possesses an infinite context window today. The challenge for future development then shifts from extending raw attention spans to optimizing the latency and efficiency of these recursive loops, potentially through asynchronous parallelism.
Real-World Implications and Future Outlook
The advent of Recursive Language Models heralds a new era for AI applications demanding deep understanding of extensive and complex information:
- Legal Document Analysis: Automatically sifting through thousands of pages of legal contracts to identify specific clauses, discrepancies, or relevant precedents, a task currently requiring immense human effort.
- Scientific Research: Processing vast scientific literature, research papers, and experimental data to uncover novel correlations, synthesize findings, or identify gaps in knowledge.
- Complex Codebase Comprehension: Understanding and reasoning over entire software repositories, enabling automated code reviews, bug detection, or refactoring suggestions at an unprecedented scale.
- Financial Auditing and Compliance: Analyzing large financial reports and regulatory documents to ensure compliance and identify potential risks or anomalies.
- Personalized Education: Adapting learning materials to individual students by understanding their entire learning history, preferences, and progress across countless documents and interactions.
While RLMs unlock immense potential, future research will focus on optimizing the latency of these recursive processes, potentially through techniques like asynchronous parallelism, where multiple sub-LLM calls and code executions can happen concurrently. The path is clear: robust reasoning in AI lies in the symbiotic relationship between neural intuition and symbolic orchestration.
Conclusion
The "Context Rot" problem has been a persistent bottleneck for Large Language Models, hindering their ability to effectively process vast and information-dense inputs. MIT's Recursive Language Models (RLMs) offer a revolutionary solution by treating long prompts as external environments and empowering LLMs to programmatically decompose, process, and aggregate information through generated Python code. By embracing a neuro-symbolic architecture that combines the fuzzy intuition of neural networks with the rigid structure of symbolic logic, RLMs not only extend the effective context window to millions of tokens but also achieve unprecedented performance and cost efficiency on complex reasoning tasks. This paradigm shift paves the way for a new generation of AI systems capable of tackling real-world problems demanding deep, comprehensive understanding of truly massive datasets.
Further Reading
- Neuro-Symbolic AI Architectures
- Advanced Techniques for Long Context in LLMs
- The Role of Code Generation in AI Reasoning
- Benchmarking LLMs for Complex Information Retrieval
- Challenges in Scaling AI with Infinite Context
- The Future of Generative AI and External Tools