Corrective RAG-Fixing the Blind Spots of Traditional RAG Systems
Introduction
The rise of LLMs has ushered in a new era of AI, capable of generating coherent and contextually relevant text. However, a persistent challenge remains: ensuring the factual accuracy and up-to-dateness of these models. This is where Retrieval Augmented Generation (RAG) stepped in, offering a robust solution by grounding LLM responses in external, verifiable knowledge bases. Yet, even traditional RAG systems have their limitations, often falling prey to what is termed blind trust in retrieved information.
This blog post delves into the evolution of RAG, highlighting the inherent problems of its traditional implementation and introducing Corrective Retrieval Augmented Generation (CRAG) as a sophisticated framework designed to overcome these hurdles. We will explore CRAG's intelligent mechanisms, from evaluating retrieved context to dynamically seeking external knowledge, ultimately leading to more reliable and accurate AI-generated responses.
What is Retrieval Augmented Generation (RAG)?
At its core, RAG enhances LLMs by providing them with access to an external knowledge base during the generation process. This prevents LLMs from solely relying on their pre-trained, sometimes outdated or generalized, internal knowledge, thereby reducing instances of factual inaccuracies or "hallucinations."
The Typical RAG Workflow Steps
-
User Query:
An input question or prompt is received from the user. -
Embedding Model:
Converts the user query into a numerical vector representation, called an embedding, which captures the semantic meaning of the query. -
Vector Database:
Stores a large collection of documents (e.g., PDFs, articles, internal reports), each also converted into vector embeddings. -
Semantic Search & Retrieval:
Uses the query's vector embedding to perform a semantic search in the vector database, retrieving documents or text chunks whose embeddings are most similar to the query. These are called retrieved contexts. -
Augmentation:
Combines the original user query and the retrieved contexts, then feeds them into a Large Language Model (LLM) to augment the prompt with relevant external information. -
Generation:
The LLM processes the augmented prompt and generates a comprehensive response grounded in the provided contexts.
Key Insight: RAG operates as a three-step process: Retrieval → Augmentation → Generation
graph TD
A[User Query] --> B{Embedding Model}
B --> C[Query Vector]
C --> D[Semantic Search in Vector Database]
D --> E[Retrieved Contexts Relevant Docs]
E --> F{Augmentation: Query + Contexts}
F --> G[Large Language Model LLM]
G --> H[Generated Response]
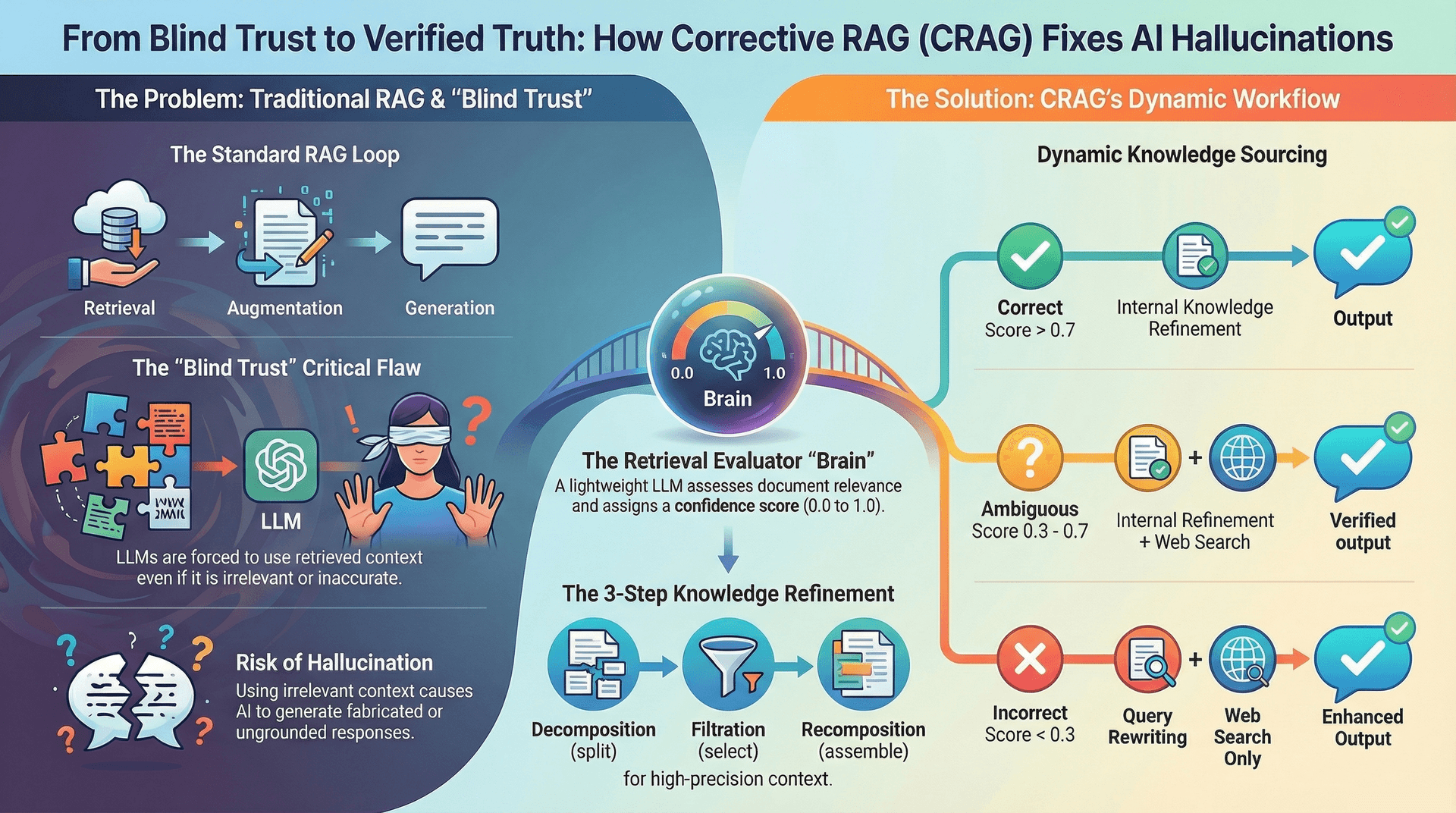
The Problem with Traditional RAG: "Blind Trust" and Hallucinations
Despite its advantages, traditional RAG suffers from a critical flaw: the LLM's "blind trust" in the retrieved contexts. If the documents retrieved from the vector database are irrelevant, inaccurate, or "out-of-distribution" for the user's query, the LLM is still compelled to use them. This often leads to the LLM generating incorrect, misleading, or even entirely fabricated answers - a phenomenon known as hallucination.
Practical Example of Failure
Consider a scenario where a user asks:
What is a transformer in deep learning?
However, the internal knowledge base only contains documents about classical machine learning algorithms like decision trees, random forests, and XGBoost, with no information on modern deep learning architectures like transformers.
In a traditional RAG system:
-
The query
What is a transformer in deep learning?
is embedded. - The semantic search might return vaguely related machine learning documents (e.g., documents discussing neural networks or general ML concepts, even if they don't mention transformers).
- The LLM, despite receiving irrelevant context, will attempt to synthesize an answer about transformers using these documents.
- Critical Issue: If the LLM has parametric knowledge of transformers (from its pre-training), it might ignore the irrelevant context and still generate a comprehensive, but ungrounded, answer about transformers. This is a hallucination because the answer is not derived from the provided context, violating the core principle of RAG.
Warning: Such inaccuracies can have severe repercussions, particularly in professional environments where factual correctness is paramount.
Introducing Corrective RAG (CRAG) as a Solution
Corrective Retrieval Augmented Generation (CRAG) is an advanced RAG variant specifically engineered to address the "blind trust" problem. Instead of passively accepting retrieved documents, CRAG actively evaluates their quality and relevance, dynamically adapting its strategy to ensure accurate and reliable information is used for generation.
Deep Dive into CRAG Architecture
CRAG introduces a sophisticated orchestration layer that critically assesses the retrieved documents and intelligently decides the subsequent steps in the generation pipeline.
The Role of the Retrieval Evaluator
A central component of CRAG is the
Retrieval Evaluator. This is typically a lightweight LLM or a fine-tuned
model (the original paper used a fine-tuned
google-t5/t5-large model, though a
general-purpose LLM can serve as a substitute for
practical implementations) that sits between the initial
retrieval step and the final LLM generation.
Primary Functions of the Retrieval Evaluator
-
Assess Relevance:
Evaluate the quality and usefulness of the retrieved documents for the given user query. -
Determine Confidence:
Assign a relevance score (e.g., 0.0 to 1.0) to each document. -
Trigger Actions:
Based on these scores, it categorizes the retrieval outcome into three distinct cases, each prompting a different corrective action.
Three Retrieval Cases and CRAG's Corrective Actions
The Retrieval Evaluator classifies the retrieved documents' relevance into three categories: Correct, Incorrect, and Ambiguous.
Case 1: Relevant (Correct)
- Condition: At least one retrieved document has a high relevance score (e.g., > 0.7), indicating it is highly relevant and sufficient to answer the query.
- Action: CRAG proceeds with an enhanced RAG process involving Knowledge Refinement (detailed below) before passing the refined documents to the LLM for response generation.
Case 2: Not Relevant (Incorrect)
- Condition: All retrieved documents have low relevance scores (e.g., <= 0.3), meaning they are entirely irrelevant or insufficient.
- Action: CRAG initiates an external knowledge search, typically using a web search tool (like Tavily), to find accurate and up-to-date information. The LLM then generates a response based on these external search results, also undergoing refinement.
Case 3: Ambiguous
- Condition: No single document scores highly, but multiple documents show moderate relevance (e.g., between 0.3 and 0.7). The retrieved documents are partially relevant or incomplete.
- Action: CRAG performs a dual approach: it uses the partially relevant internal documents for knowledge refinement and simultaneously conducts an external knowledge search. The system then merges the refined internal and external knowledge to create a comprehensive context for the LLM's response generation.
Key Insight: This dynamic approach ensures CRAG avoids blindly trusting potentially flawed initial retrieval, making it significantly more robust than traditional RAG.
graph TD
A[User Query] --> B{Retrieve Documents from Vector DB}
B --> C{Retrieval Evaluator LLM Judge}
C -- Relevance Score --> D{Evaluate Documents}
D -- Correct --> E[Knowledge Refinement Internal]
D -- Incorrect --> F[Query Rewriting & Web Search]
D -- Ambiguous --> G[Knowledge Refinement Internal + Query Rewriting & Web Search]
E --> H[Generate Response with LLM]
F --> H
G --> I[Merge Internal & External Contexts]
I --> H
Knowledge Refinement: Decomposing, Filtering, and Recomposing
Even when documents are deemed "Correct," traditional RAG's standard chunking methods (e.g., splitting text every 900 characters) can introduce noise, as chunks might contain both relevant and irrelevant information for a specific query. Knowledge Refinement addresses this by meticulously processing the retrieved documents.
The Three-Step Refinement Process
-
Decomposition:
Break each retrieved document into smaller, focused parts (usually sentences or short passages). -
Filtration:
Evaluate each part for relevance to the query using a specialized model. Keep only the most relevant pieces. -
Recomposition:
Combine the filtered, relevant parts into a concise, targeted context for the LLM.
- Decomposition → Break down documents for precision
- Filtration → Strictly select only what matters
- Recomposition → Assemble a focused, high-quality context
Flow Change: This effectively transforms the RAG flow from:
retrieve → generate
to:
retrieve → refine → generate
Retrieval Evaluation: Thresholding Logic for Verdicts
To enable the dynamic routing described above, CRAG implements a robust retrieval evaluation mechanism using thresholding logic. An LLM acts as the Retrieval Evaluator, assigning a numerical relevance score (e.g., 0.0 to 1.0) to each retrieved document chunk.
Thresholds for Verdicts
Tunable Parameters: These define how document relevance is categorized:
-
UPPER_TH(e.g., 0.7):
Documents scoring above this threshold are considered highly relevant. -
LOWER_TH(e.g., 0.3):
Documents scoring below or equal to this threshold are considered minimally relevant.
How it works: Scores above
UPPER_TH trigger the "Correct" verdict,
scores below or equal to LOWER_TH trigger
"Incorrect," and scores in between lead to "Ambiguous."
| Verdict | Condition | Description |
|---|---|---|
| Correct |
At least one document's score >
UPPER_TH
|
High-quality retrieval; proceed with refinement. |
| Incorrect |
All documents' scores <=
LOWER_TH
|
Insufficient retrieval; requires external search. |
| Ambiguous |
No document scores >
UPPER_TH, but at least one >
LOWER_TH
|
Mixed relevance signals; requires refinement and external search. |
Note: For final answer generation, only documents with a relevance score greater than
LOWER_THare used as context, regardless of the overall verdict. This ensures that even in "Ambiguous" or "Incorrect" scenarios where external search fills gaps, only truly useful internal chunks contribute to the answer.
Web Search Integration: Expanding Knowledge Horizons with Tavily
When the Retrieval Evaluator issues an "Incorrect" verdict, indicating a lack of relevant internal knowledge, CRAG seamlessly integrates external knowledge searching. This typically involves using a specialized search API to query the vastness of the internet.
About Tavily Search API
Tools like Tavily are purpose-built for this. Tavily's Search API is designed to deliver LLM-ready context, offering features like:
- Structured JSON results
- Relevance scores
- Citations
These are crucial for enhancing factual accuracy and mitigating outdated information.
Reusability: The raw results from the web search undergo the same Knowledge Refinement process (Decomposition, Filtering, Recomposition) as internal documents. This reusability of the
refineandgeneratenodes is a significant architectural advantage.
Query Rewriting for Better Search Results
User queries are often vague, underspecified, or lack critical keywords. Directly feeding such queries to a web search engine can yield suboptimal results. To optimize external search, CRAG introduces a Query Rewrite step.
When the system determines an external search is necessary (i.e., for "Incorrect" or "Ambiguous" verdicts), a dedicated LLM is employed to rewrite the original user query into a more precise, keyword-rich, and search-engine-friendly format.
Query Rewriting Instructions
The LLM is prompted with instructions such as:
- Rewrite the question into a web search query composed of keywords.
- Keep the rewritten query concise (e.g., 6-14 words).
-
Add time constraints if the original question
implies recency (e.g.,
recent AI news
becomesAI news last month
). - Return only the rewritten query in a structured format.
Handling Ambiguous Knowledge: Merging Internal & External Context
The "Ambiguous" verdict represents a critical scenario where some internal documents are weakly relevant but not enough on their own, requiring external supplementation. CRAG's intelligent design handles this by dynamically merging knowledge from both internal and external sources.
Dynamic Input Adaptation
The Refine node adapts its input based
on the verdict to ensure the LLM receives
the most relevant context:
- Correct: Uses only the internal good_docs.
- Incorrect: Uses only the web_docs from external search.
- Ambiguous: Combines both good_docs (internal) and web_docs (external) for a richer, more complete context.
This approach ensures that, regardless of the retrieval outcome, the LLM is always grounded in the most relevant and accurate information available.
Key Benefits of Corrective RAG (CRAG)
CRAG offers significant improvements over traditional RAG systems:
- Reduced Hallucinations: By critically evaluating retrieved documents, CRAG ensures that LLMs are not misled by irrelevant or inaccurate information, significantly reducing the generation of fabricated responses.
- Enhanced Factual Accuracy: Dynamic knowledge sourcing, including intelligent web search and rigorous refinement, ensures responses are grounded in the most relevant and accurate information available.
- Improved Robustness: CRAG is resilient to issues like outdated internal knowledge bases or poorly formulated user queries, as it can adapt its strategy to find reliable information.
- Greater Adaptability: The system can seamlessly integrate new information from the web, keeping its knowledge current without requiring constant retraining of the LLM.
- Higher Quality Responses: Knowledge refinement at the sentence level ensures that only highly relevant information contributes to the final answer, leading to more precise and coherent output.
- Transparency and Trust: By sourcing information more intelligently, CRAG-powered systems can potentially offer better traceability to the sources of their answers, building greater user trust.
Real-World Applications
Advanced RAG techniques like CRAG are transforming a wide range of industries. Below are some key application areas:
-
Customer Service Chatbots:
Deliver highly accurate, up-to-date answers to complex customer queries by integrating internal product manuals with recent troubleshooting forums and external sources. -
Enterprise Knowledge Management:
Empower employees to quickly access precise information from vast internal document repositories and external industry news. -
Healthcare:
Assist medical professionals with real-time access to the latest research, treatment protocols, and patient data, improving diagnostic accuracy. -
Financial Analysis:
Summarize financial reports, market news, and regulatory updates, enabling analysts to make informed decisions. -
Legal Research:
Retrieve relevant statutes, case law, and legal precedents from extensive databases and recent rulings.
Note: CRAG's ability to combine internal and external knowledge sources makes it especially valuable in domains where information changes rapidly or accuracy is critical.
Conclusion
Traditional Retrieval Augmented Generation marked a significant step forward in making LLMs more reliable. However, its inherent "blind trust" in retrieved contexts presented a new set of challenges, particularly the risk of hallucination.
Corrective RAG (CRAG) represents a powerful evolution, introducing a self-aware mechanism that intelligently evaluates retrieval quality and dynamically adapts its strategy. By incorporating sophisticated knowledge refinement, proactive web searching, and smart query rewriting, CRAG ensures that LLMs are always grounded in the most accurate and relevant information available, leading to truly robust and trustworthy AI applications.
Further Reading
- Advanced Retrieval Augmented Generation Techniques
- LLM Evaluation Metrics for RAG Systems
- Vector Databases for Enterprise AI
- The Role of LangChain and LangGraph in Orchestrating LLM Applications
- Techniques for Mitigating LLM Hallucinations